Is your site unfriendly to search engine spiders like MSNBot?
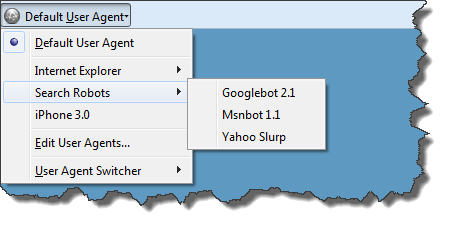
Microsoft blogger Eytan Seidman on their MSN Search blog offers some very useful specifics on what makes a site crawler unfriendly, particularly to MSNBot: An example of a page that might look “unfriendly” to a crawler is one that looks like this: https://www.somesite.com/info/default.aspx?view=22&tab=9&pcid=81-A4-76§ion=848&origin=msnsearch&cookie=false….URL’s with many (definitely more than 5) query parameters have a very low […]
Podcasts on Business Blogging and SEO

A few weeks back I posted a couple of podcasts from the Professional Association of Innkeepers International Conference 2006. At that Conference I spoke at four different sessions. The two sessions I already posted were on email marketing — one on the fundamentals and the other on advanced topics. Now I have my other two […]
Beating the Google Sandbox (TrustBox)
My latest SEO Report Card addresses the mythical monster that continues to rear its ugly head… the “Google Sandbox.” No I’m not going to get into a debate about whether it exists or not. It does. End of discussion. 🙂 What I am going to do is try to render some assistance to some nice […]
Editing Wikipedia for SEO?
It’s getting a bit ridiculous how often Wikipedia shows up on the first page of Google for just about every search imaginable. Micropersuasion has noticed it for brand searches. Google’s getting a bit lazy I think to give Wikipedia carte blanche access to page 1 of the SERPs (Search Engine Results Pages). Often times Wikipedia […]
Wikipedia changes the game, but the game isn’t over

I blogged last month about Wikipedia and SEO. There are a number of considerations when making edits, creating entries, and passing the “Notability” test — practices to avoid so you don’t run afoul of their guidelines and so on. Well folks, the game has changed. Wikipedia just instituted nofollows on all external links. This had […]
Link building into “Blog Carnivals”

You may or may not have heard of a blog carnival. Blogging colleague Toby Bloomberg first introduced me to the concept and I must say, as a link building afficionado, my eyes lit up at the potential these traveling columns have for building links. A blog carnival is, in effect, a column on a particular topic that is passed […]
SEO Report Card: Escaping the Google Sandbox
This article was originally published under Practical Ecommerce. New sites are always at a disadvantage when it comes to ranking well in Google, particularly when the domain name is new, too. This phenomenon, known by some as the “Google Sandbox” and by others as the “TrustBox,” is not a myth. It is very real and […]
Getting organized – a progress report

On January 1st on the MarketingProfs’ Daily Fix where I am a contributing blogger, I proclaimed my New Year’s Resolution to the world — which was to implement an amazing system for unprecedented gains in productivity and organization that I had discovered. That system — called GTD by its followers — is based on the […]
Free archived webinar on link building from me and Eric Ward

I got permission from MarketingProfs to post an archived version of the webinar Eric Ward and I presented last year on link building. It is 90 minutes long and has some good actionable advice and tips and tricks, and it looks at link building from a more wholistic perspective than just SEO. I hope you […]